Prawdopodobnie nie słyszałeś/aś o projekcie Kona. W całym internecie zaledwie 7 stron wspomina o tym niezwykle zaawansowanym przedsięwzięciu firmy Google (teraz już osiem). Kona jest latarnią współczesnej rewolucji obliczeniowej, która zmienia świat dot com w świat machine learningu.
Już tak elementarne obliczenia na poziomie licealnym są wykorzystywane w niektórych algorytmach ML (oczywiście z odpowiednio większym skomplikowaniem i ze wsparciem dodatkowych modeli matematycznych).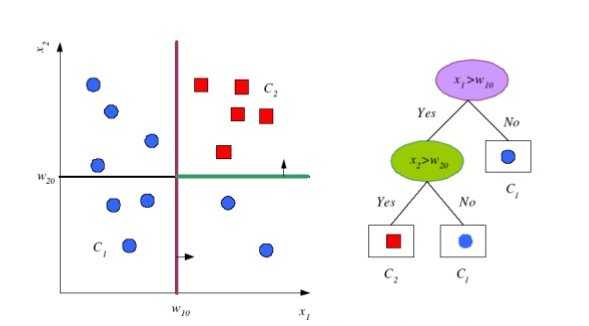

Po latach prowadzenia technologicznych firm, tysiącach patentów i 21 doktoratach honoris causa, Ray Kurzweil porzucił etos przedsiębiorcy-wynalazcy i po raz pierwszy został zatrudniony w obcej firmie. Tą firmą stało się Google. Jeden z jej założycieli, Larry Page, przekonał Kurzweila do tego kroku w trakcie dyskusji nad możliwością stworzenia prawdziwie inteligentnego komputera. Kurzweil początkowo próbował wynegocjować moc obliczeniową oraz dane firmy Google dla własnych przedsiębiorstw, lecz ostatecznie negocjacje zamieniły się w rozmowę rekrutacyjną – skuteczną dla obu rozmówców, ponieważ firma Google przechwyciła legendę branży technologicznej, a Kurzweil otrzymał dostęp do rozległych zasobów korporacji oraz budżet na zbudowanie dużego zespołu.
Ostatnie kilka lat pracy zespołu skupiło się wokół projektu Kona. To pierwszy krok na drodze do AI rodem z książek fantastycznych, na których wychowywał się 73-letni Kurzweil. Adresuje podstawową cechę wszystkich ludzi, która jednocześnie odróżnia nas od wszystkich pozostałych zwierząt: zdolność do rozumienia języka i posługiwania się nim. Kona ma sprawić, że komputer będzie wykorzystywać język dokładnie tak jak człowiek – będzie czytać i pisać artykuły, wyciągać wnioski z książek, dyskutować w internecie, odpisywać na maile. De facto ma to robić lepiej niż człowiek, ponieważ napisanie tekstu czy przeczytanie książki nie zajmie cały dzień, ale zaledwie okamgnienie.
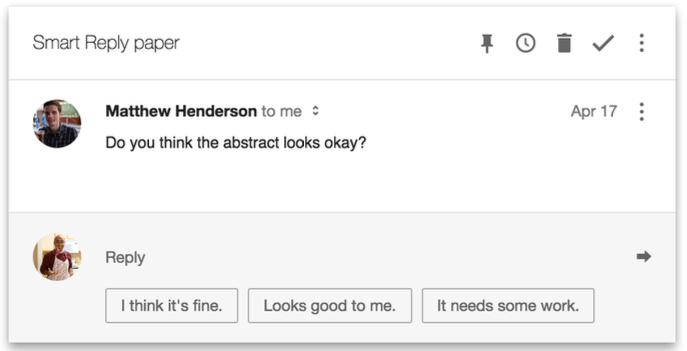
Na razie Kona zaczyna od ostatniej z wymienionych czynności – odpowiadania na maile. Kod programistów w zespole Kurzweila odpowiada za funkcję Smart Reply w Gmailu. Mimo że wygląda banalnie:
W rzeczywistości jest prototypem niesamowicie złożonej technologii, która ma doprowadzić komputery do całkowitego posługiwania się językiem.
Ma, ponieważ na razie radzi sobie różnie:
Za tym prototypem jak i całym projektem Kona stoi technologia, którą można streścić do następującej gradacji: AI -> machine learning -> deep learning.
AI i ML
Nie bez powodu posługujemy się raczej angielskimi niż polskimi określeniami. Nie zawsze obce terminy technologiczne warto dosłownie tłumaczyć – dzięki temu angielski computer jest dla nas komputerem, a nie obliczaczem. Podobnie jak przyjął się skrót PC, znacznie częściej w polskim języku jest używany skrót AI (ang. artificial intelligence) niż SI (pol. sztuczna inteligencja). W przypadku machine learningu dochodzi dodatkowa warstwa subtelności, ponieważ tłumaczenie na uczenie maszynowe rozmywa oryginalne znaczenie.
AI to szeroki zbiór różnorodnych technologii. ML to jedno z doprecyzowań AI. Zostało zaproponowane już w latach 50., gdy Arthur Samuel wpadł na pomysł by – raczkujące wtedy – komputery nie tylko uczyć, ale również nauczyć samodzielnej nauki. Taki ruch w pierwszej chwili sugeruje zdjęcie części pracy z programisty (słynne „AI zabiera pracę”), jednak głównym bogactwem machine learningu są algorytmy symulujące ludzkie rozumowanie. Oddanie części kroków algorytmicznych w całkowite władanie komputera sprawia, że znacznie lepiej radzi sobie z rozpoznawaniem wzorców, kontrolą nowych sytuacji i poruszaniem się w rzeczywistości, w której rzadko występują dane od linijki.
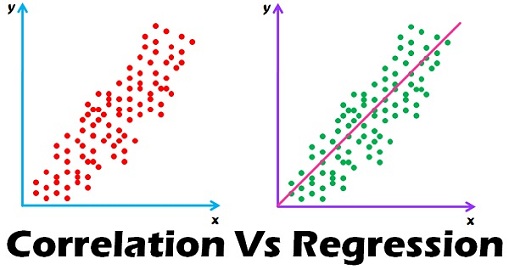
Przechodząc z dość abstrakcyjnych opisów do realnych wdrożeń, machine learning zaczyna się już od bliskich związków z korelacją. Te same dane, które służą obliczeniu korelacji, mogą być wykorzystane w wyprowadzeniu regresji:
Już tak elementarne obliczenia na poziomie licealnym są wykorzystywane w niektórych algorytmach ML (oczywiście z odpowiednio większym skomplikowaniem i ze wsparciem dodatkowych modeli matematycznych).
Drugim popularnym wdrożeniem w ML są drzewa decyzyjne, gdzie na podstawie określonych danych budowana jest ścieżka doprowadzająca do właściwych rezultatów:
Jednak perłą w koronie ML stał się deep learning (pol. głęboka nauka). To właśnie on odpowiada za niesamowitą popularność tematyki AI w ostatnich latach. Powstał już w latach 90., ale dopiero niesamowity rozwój procesorów i dostępność ogromnych mocy obliczeniowych umożliwiła rozpoczęcie wdrażania deep learningu w szerokiej skali.
DL
Deep learning bezpośrednio inspiruje się wynalazkiem kilku miliardów lat ewolucji – mózgiem.
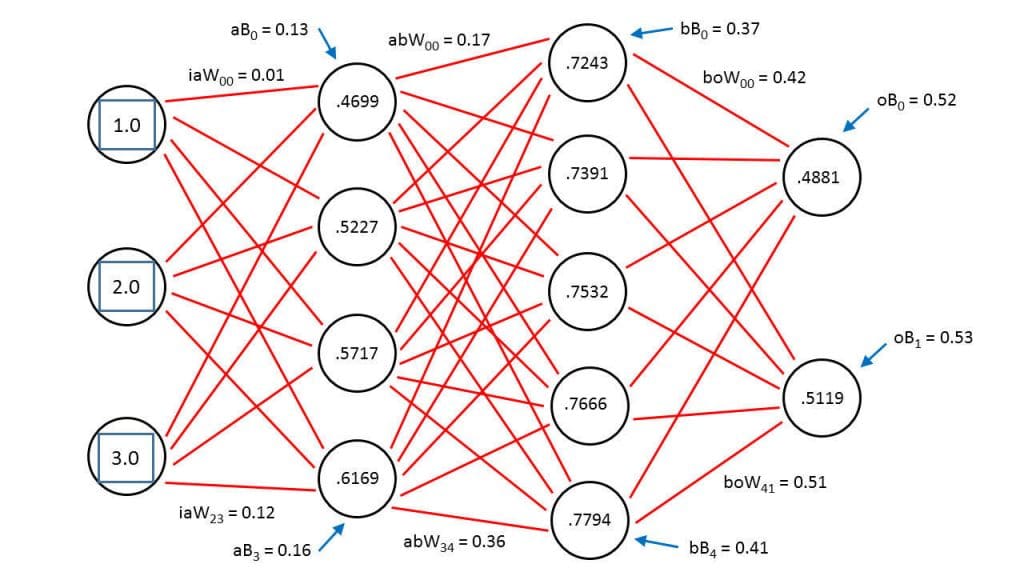
Mózg składa się z sieci połączonych komórek nerwowych. Ogromny sukces tego narządu można sprowadzić do dwóch zdolności tych komórek: przekazywania oraz modyfikacji sygnału. Te cechy zgrubnie zostały odtworzone za pomocą komputerowych sieci neuronowych, gdzie warstwy pojedynczych jednostek są ze sobą wzajemnie połączone i posiadają określone wagi zmieniające sygnał. Zarówno mózg jak i sztuczne sieci neuronowe zawdzięczają możliwość uczenia elastycznemu dostosowywaniu połączeń oraz wag.
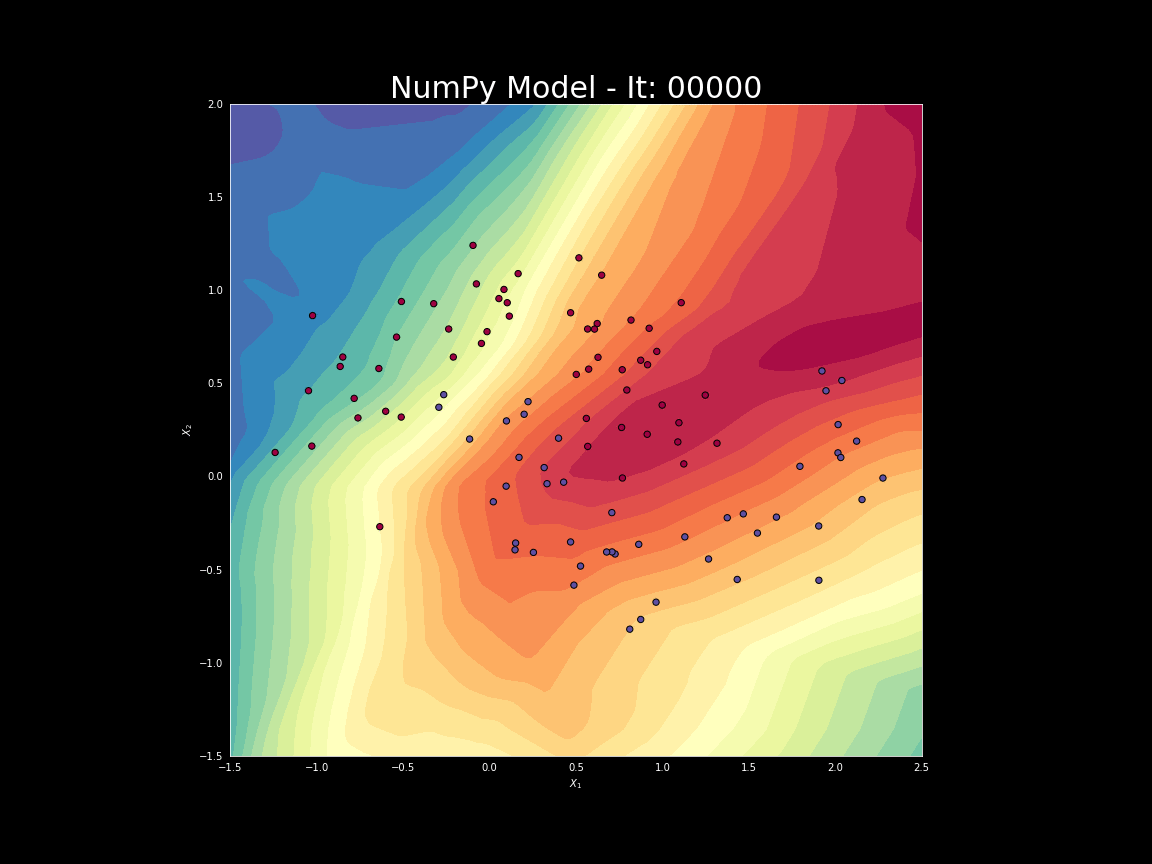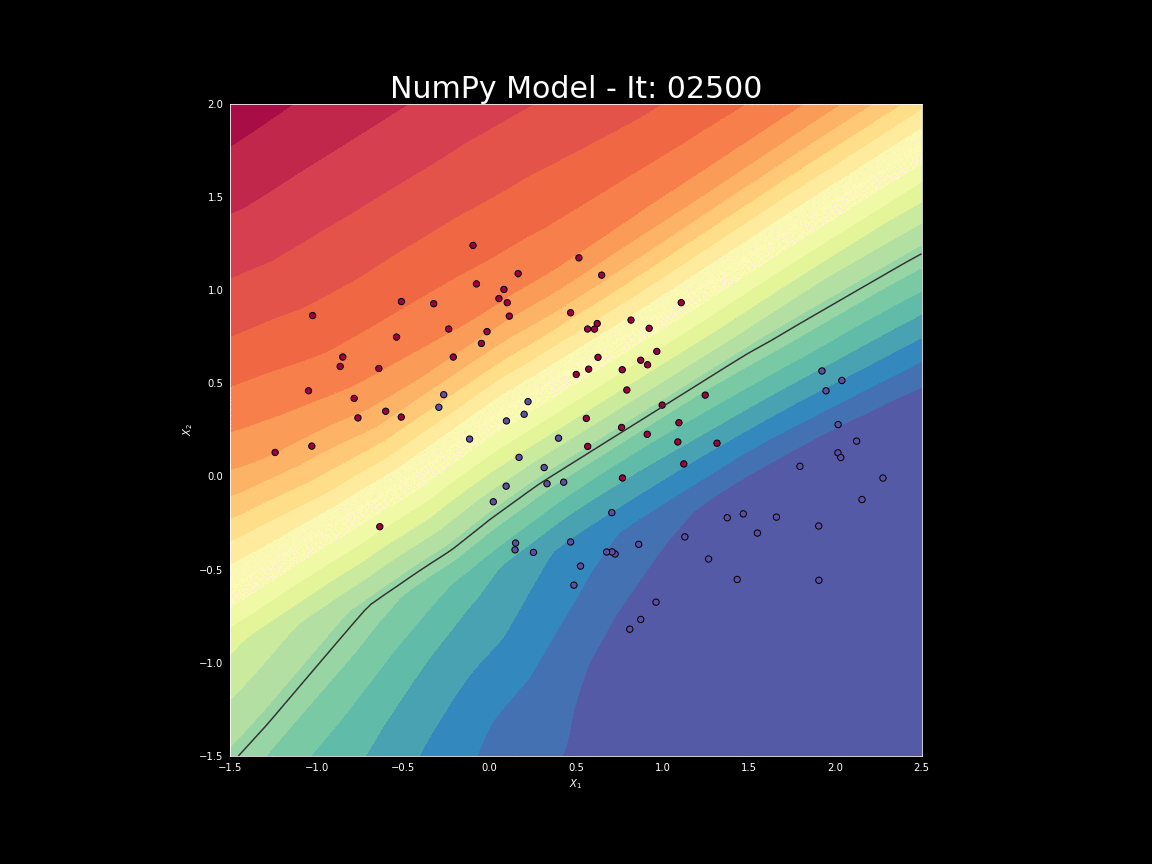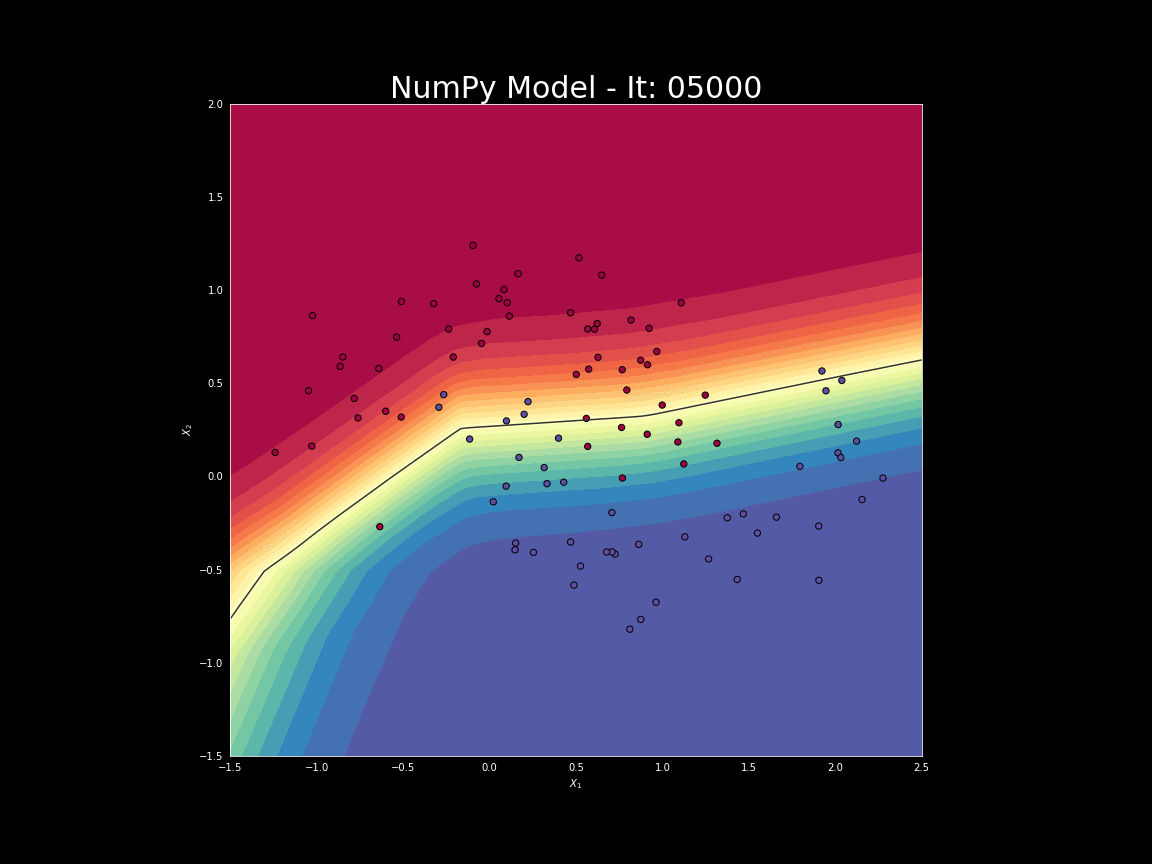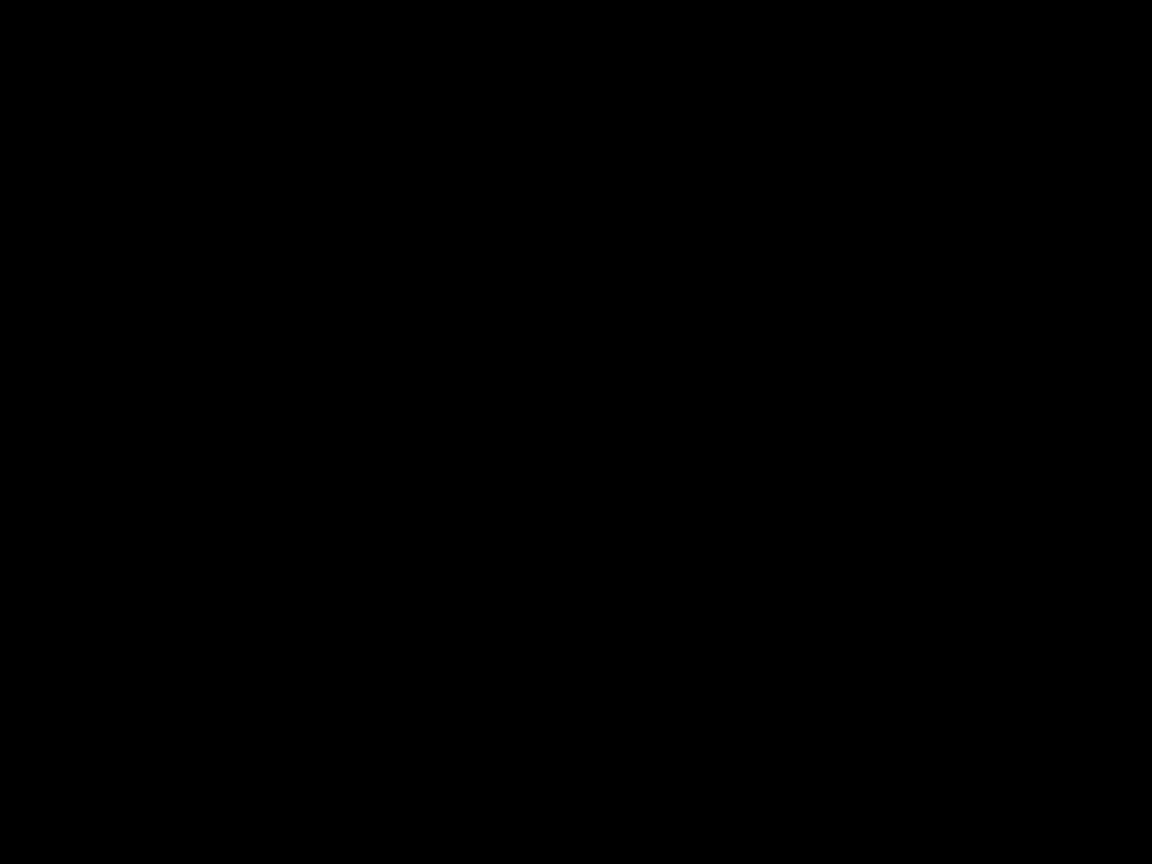
Deep learning wykorzystuje wiele warstw sieci (stąd przymiotnik: głęboki) formowanych w wielu krokach. Przykład formowania sieci i dojścia do właściwego rozdzielenia dwóch zbiorów:
Posiada wiele wad – wymaga ogromnych ilości danych, istotnej mocy obliczeniowej, dokładna zasada rozumowania jest nieznana – ale jednocześnie jest technologią, która współcześnie najbardziej zasługuje na określenie: „sztuczna inteligencja”. Deep learning już udowodnił swoją skuteczność w opanowywaniu umiejętności, które jeszcze kilkanaście lat temu były uważane za nieosiągalne algorytmicznie, takich jak prowadzenie samochodu w rzeczywistym ruchu drogowym.
Zwrot w kierunku danych
Rzeczywiście algorytmy machine learning zdjęły część pracy z programistów. Przygotowanie klasycznego oprogramowania, które rozpoznaje pieszych w ruchu drogowym byłoby ekstremalnie czasochłonne. W przypadku machine learningu kwestię rozpoznawania zostawiamy złożonym algorytmom, natomiast głównym zadaniem jest tylko przygotowanie odpowiedniej ilości danych do nauki.
Słowo „tylko” było tu zdecydowanie sarkazmem. Zebranie danych, przygotowanie, a następnie opisanie w objętości liczonej w milionach obiektów jest poważnym problemem we wszelkich zastosowaniach ML. Paradoksalnie większość działań naukowych skupia się nie wokół budowy i poprawy sieci neuronowych, ale wokół odpowiedniego opracowywania danych, a także ich właściwego wykorzystania. Przykładowo projekty ML powszechnie borykają się z overfittingiem (pol. zbyt dokładne dopasowanie), gdzie algorytm nieświadomie przyzwyczaja się do nieistotnych ale częstych cech (np. piesi w zielonych kurtkach), przez co nie radzi sobie z sytuacjami odstającymi (np. piesi w czerwonych kurtkach).
Z uwagi na istotność i czasochłonność procesu przygotowywania danych, właśnie ten element krajobrazu machine learningu nie tylko generuje problemy, ale również… może być celem ataku.
Łamanie machine learningu
W ostatnich latach prawdziwą furorę robią ataki na narzędzia deep learning. Idea jest prosta: za pomocą manipulacji danych, algorytmy są zmuszane do zwrócenia całkowicie złych wyników, takich jak ten:
Na najbardziej podstawowym poziomie dzielą się na white-box (pol. biała skrzynka) oraz black-box (pol. czarna skrzynka, ale nie lotnicza). W trakcie ataku white-box badacze mają dostęp do całego systemu i próbują go wprowadzić w błąd wykorzystując bezpośrednio jego zasoby. To rzadka sytuacja, możliwa raczej tylko w warunkach laboratoryjnych lub przy wewnętrznych testach.
Znacznie bardziej atrakcyjne są ataki black-box, gdzie atakujący operuje wyłącznie z zewnątrz, bez żadnej współpracy z autorami algorytmy, a także bez wiedzy o wewnętrznych mechanizmach (stąd czarna skrzynka – archetyp nieznanego mechanizmu, w którym widzimy tylko to co pojawia się na początku i na końcu). Do tej pory takie ataki wymagały ogromnych mocy obliczeniowych i milionów prób by osiągnąć efekt taki jak wyżej (zmiana pandy w gibona), jednak niedawno pojawiła się świetna publikacja, która łamie algorytmy za pomocą niecałego tysiąca odpytań:
GenAttack: Practical Black-box Attacks with Gradient-Free Optimization
SEO a ML
Celowo przez cały artykuł nie padło ani jedno słowo o SEO. Każdy czytelnik, jako inteligentna nie-maszyna dysponująca w głowie pełnym wachlarzem algorytmów nauczania, może bez problemu odnieść informacje i wnioski w stosunku do środowiska wyszukiwania. Trudno określić jakie dokładnie algorytmy są klasyczne, a jakie już przeszły pod strzechy ML, jednak swego czasu sformułowaliśmy hipotezę: przeniesienie algorytmu do core oznacza jego usamodzielnienie w kontekście ML. Jeśli jest prawdziwa, wszystkie powyższe informacje są ekstrapolowalne zarówno na Pingwina jak i na Pandę. Jednak jak pokazuje projekt Kona, najbardziej interesujące luki mogą się kryć w rozumieniu treści przez wyszukiwarkę Google.
Zalinkowane źródła: Arxiv.org. Źródła grafik: KurzweilAI.net, KeyDifferences.com, LewisGavin.co.uk, Medium.com, Arxiv.org.