
Screaming Frog SEO Spider to narzędzie doskonale znane każdej agencji SEO, pozycjonerowi, a niejednokrotnie i właścicielowi strony. Dlaczego? Ze względu na charakterystyczną nazwę? Otóż nie. W wolnym tłumaczeniu “krzycząca żaba” to narzędzie, które pozwala nam uzyskać wiele informacji o witrynie, a tym samym przeprowadzić jej analizę pod kątem onsite.
W tym artykule skupimy się na aktualizacji, która w dużym stopniu zwiększyła już i tak szerokie możliwości jakie dawał nam Screaming Frog. Pozwolimy sobie jednak wymienić kilka tych najważniejszych, jakie dawał nam crawler jeszcze przed aktualizacją:
- Title, description, H1, H2 – te i wiele innych elementów strony zwraca nam crawler, dzięki czemu wszystkie dane mamy w jednym miejscu, a ich analiza jest znacznie prostsza.
- Kod odpowiedzi HTTP – narzędzie zwraca nam kody odpowiedzi dla każdej podstrony.
- Linki wychodzące – crawl podąża nie tylko za linkami wewnętrznymi, zwraca nam także listę linków wychodzących wraz z informacją na jakich podstronach się znajdują, a także jaki jest ich anchor.
- Sitemap.xml – Screaming Frog daje także możliwość wygenerowania pliku sitemap.xml.
Screaming Frog SEO Spider 12.0 – aktualizacja
Wersja 12.0 zaskoczyła licznymi rozwiązaniami, które skutecznie ułatwiają analizę danych. Poniższa lista to tak naprawdę tylko kilka udogodnień jakimi zadziwił nas Screaming Frog.
1. Integracja z PageSpeed Insights
Dzięki temu połączeniu Screaming Frog ma możliwość pobierania danych dla każdej podstrony danej witryny. Co to oznacza? Za pomocą jednego kliknięcia otrzymujesz dane, które w normalnych warunkach zdobywałbyś przeklikując się pomiędzy wszystkimi podstronami analizowanej witryny, a dedykowanym narzędziem od Google, jakim jest PageSpeed Insights. Jak zacząć korzystać z tego udogodnienia?
» Najpierw musimy wybrać interesujące nas metryki i skonfigurować dostęp do API:
Configuration -> API Access -> PageSpeed Insights
» W celu uzyskania darmowego klucza API klikamy w link dostępny pod “here”:
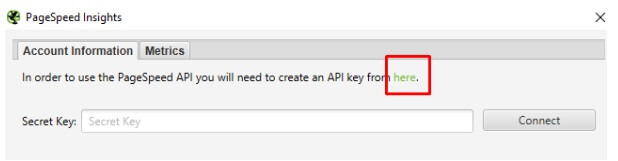
» Logujemy się do konta Google i tworzymy dane logowania:
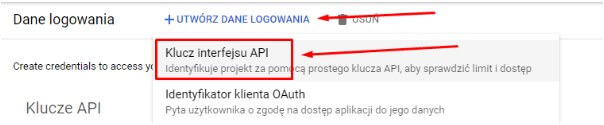
» Następnie w oknie wyszukiwania wpisujemy nazwę usługi, dla której chcemy włączyć API i klikamy “Włącz”:

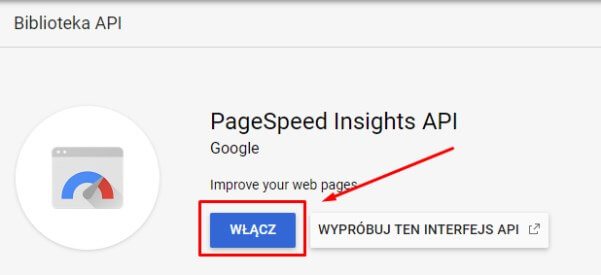
Teraz możemy wrócić już do naszego narzędzia i wkleić wygenerowany klucz w wyznaczone do tego miejsce. Następnie przechodzimy do zakładki “Metrics” i wybieramy interesujące nas grupy danych: Overview, CrUX Metrics, Lighthouse Metrics, Opportunities, Diagnostics. Dla każdej z nich możemy indywidualnie określić potrzebne nam metryki:
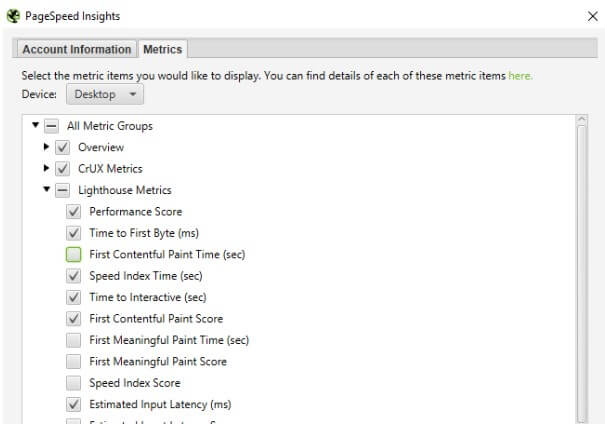
Pozostaje tylko przecrawlowanie wybranej witryny i zagłębienie się w wyniki. Na oficjalnej stronie narzędzia dostępny jest przewodnik, w którym znajdziesz szczegółowe informacje dotyczące także ogólnych ustawień (w tym instalacji narzędzia), opcji konfiguracji poszczególnych danych czy informacje na temat dostępnych zakładek. W sekcji “How to” znajdziesz również najczęściej zadawane pytania.
2. Automatyczne zapisywanie crawla
Wyczekiwany “dodatek” od października 2019 zagościł na stałe w crawlerze i choć dla niektórych może wydawać się niczym wyjątkowym zakładamy, że dla większości to stumilowy krok do przodu. Ile razy zdarzyło Ci się włączyć crawla dużej strony, zostawić na dłuższy czas i po powrocie zastać czarny ekran lub błąd związany np. z brakiem pamięci? Kiedy Ty załamywałeś ręce, zespół Screaming Froga pracował nad wdrożeniem automatycznego zapisywania pobranej bazy danych.
Jeżeli chcesz uniknąć takich sytuacji w przyszłości, skorzystaj z poniższego poradnika.
Automatyczny zapis jest możliwy tylko w przypadku wykorzystywania dysku do zapisania crawla, dlatego w pierwszym kroku zmień sposób przechowywania danych:
Configuration -> System -> Storage -> Mode: Database Storage
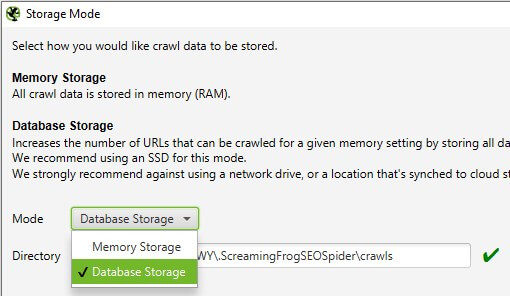
Aby ustawienia zostały włączone, należy ponownie uruchomić Screaming Froga.
Od tego momentu każdy wykonany crawl zostanie zapisany automatycznie na dysku, a dostęp do niego będzie możliwy poprzez wejście w zakładkę “Crawls”:
File -> Crawls
Pamiętaj: usuń nieużywane/niepotrzebne crawle, gdyż automatyczne zapisywanie powoduje zapełnianie się dysku.
3. Konfiguracja zakładek
Kolejne udogodnienie, dzięki któremu w szybki sposób posortujemy i wybierzemy istotne dla nas dane. Wystarczy kliknąć prawym przyciskiem myszy w wybraną zakładkę i usunąć ją z widoku.
4. Konfiguracja wykluczeń
Używając standardowych ustawień otrzymywaliśmy ogromną bazę danych, które niekoniecznie były nam potrzebne. A gdyby tak móc wybrać tylko to, co dla nas istotne, zaoszczędzając przy tym miejsce? I na to rozwiązanie wpadła załoga Screaming Froga.
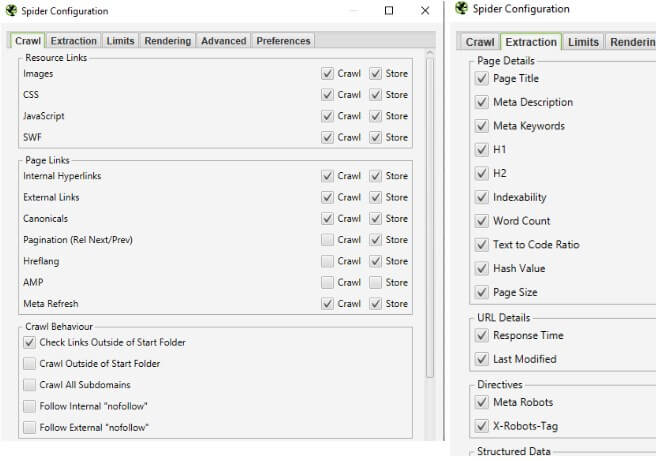
Dzięki aktualizacji możemy wykluczyć crawlowanie obrazów, plików css, js, a także elementów strony takich jak tytuł, słowa kluczowe, nagłówki i wiele innych.
Konfigurację znajdziesz w:
Configuration -> Spider -> Zakładka Crawl oraz Extraction
Dlaczego warto korzystać z narzędzi do crawlowania stron? Powyższy tekst powinien odpowiedzieć na to pytanie i zachęcić do korzystania z udogodnień, jakie zaoferował nam Screaming Frog. Sami intensywnie korzystamy z płatnej wersji tego narzędzia, dlatego zapraszamy także do zadawania pytań w komentarzach.




