
BERT (Bidirectional Encoder Representations from Transformers) to wprowadzona w 2019 r. aktualizacja, która pozwoliła na efektywniejsze przetwarzanie języka naturalnego (NLP). Jej działanie opiera się na sieciach neuronowych i uczeniu maszynowym, które umożliwiły zaawansowaną analizę kontekstową. Wprowadzenie aktualizacji było przełomowe co najmniej z dwóch powodów: algorytm tzw. deep learningu nauczył się analizować zapytania użytkowników w sposób relacyjny (a nie jak do tej pory – interpretując słowo po słowie) oraz zaczął uwzględniać tzw. stopwordsy (przyimki i spójniki np. do, i), które wcześniej były pomijane w zbiorach danych. W jaki sposób BERT pomaga wyszukiwarce interpretować zapytania użytkowników w 2021 r., czy ma to znaczenie dla SEO oraz z jakimi wyzwaniami językowymi nadal musi się mierzyć?
1. Przetwarzanie języka naturalnego
1.1. Początki NLP – test Turinga
Językiem naturalnym określamy języki (np. język polski, angielski lub francuski) służące do komunikacji interpersonalnej. W przeciwieństwie do języków formalnych (języki programowania) nie zostały stworzone przez człowieka, tylko ewoluowały w sposób naturalny i charakteryzują się zmiennością. Język formalny jest zrozumiały przez komputer, dosłowny, zwięzły oraz pozbawiony dwuznaczności. Prawdziwym wyzwaniem dla językoznawców i badaczy AI (sztucznej inteligencji) jest przetwarzanie języka naturalnego. W latach 50. XX-wieku Alan Turing próbował znaleźć odpowiedź na pytanie: czym jest myślenie? Zaprojektował słynny test Turinga, którego celem było sprawdzenie, czy podczas rozmowy tekstowej maszyna zdoła oszukać osobę prowadzącą z nią konwersację, imitując zdolności komunikacyjne. Umiejętności interpretacji i generowania języka naturalnego, które prowadzą do oszukania człowieka, że rozmawia z żywą osobą, miałyby świadczyć o inteligencji maszyny.
1.2. Co to znaczy „rozumieć język”? Kontrargument chińskiego pokoju
John Searle zaprojektował eksperyment myślowy dowodzący, że posiadanie instrumentów do wykonania danego zadania nie jest tożsame z jego rozumieniem, co podważa rzekomą inteligencję maszyny, która zdałaby test Turinga. Argument chińskiego pokoju był wymierzony w zwolenników mocnej teorii AI i ma podłoże filozoficzne, ale można go odnieść do przetwarzania języka naturalnego. Wg Searle’a dysponowanie składnią i symbolami nie jest wystarczające, ponieważ kluczowymi elementami pozwalającymi zrozumieć język są treści symboliczne (umysłowe). W eksperymencie Searle’a w chińskim pokoju jest zamknięty człowiek, który posługuje się językiem angielskim, ale nie zna ani słowa po chińsku. Pomieszczenie jest wyposażone w „wejście” i „wyjście”, a na zewnątrz znajdują się Chińczycy, którzy przekazują mężczyźnie karteczki z chińskimi znakami. Bohater eksperymentu ma do dyspozycji książkę reguł, która wskazuje, że jeśli otrzymał kartkę z zestawem znaków x, to powinien oddać kartkę z zestawem znaków y.
Mężczyzna w pokoju ma – teoretycznie – wszystko, co niezbędne do zrozumienia języka chińskiego. Potrafi tworzyć poprawne zdania i mógłby przejść test Turinga, ale brakuje mu najważniejszego, czyli świadomości semantycznej. Bohater eksperymentu myślowego nie zna znaczenia poszczególnych symboli (słów), dlatego nie moglibyśmy stwierdzić, że zna on język chiński. Według Searle’a sztuczna inteligencja jedynie symuluje znajomość języka, bo, chociaż zwraca poprawne wyniki, tak naprawdę jej rozumienie nie wykracza poza syntaktyczną znajomość reguł.
1.3. Interpretacja języka naturalnego – problemy
Język można określić jako system tworzenia znaków, ponieważ – jako kompetentni użytkownicy języka – jesteśmy w stanie tworzyć nowe słowa i zmieniać ich znaczenie. Znajomość reguł językowych to za mało, żeby zawsze prawidłowo dekodować informacje językowe; ważny jest również kontekst użycia czy stan wiedzy o świecie. Wyzwania przed którymi staje przetwarzanie języka naturalnego to m.in.:
- Polisemiczność – wpisując „zamek”, użytkownik może mieć na myśli zamek błyskawiczny, zamek jako budowlę lub zamek w drzwiach. Wieloznaczność powoduje, że bez szerszego kontekstu trudno poprawnie zinterpretować dane słowo lub wyrażenie. Problemem jest też oznaczanie części mowy: „book” może oznaczać „książkę” lub „rezerwować”.
- Homonimiczność – identyczne brzmienie i pisownia niektórych wyrazów, które mają różne znaczenie, a czasem reprezentują także inną część mowy i, w przeciwieństwie do wyrażeń polisemicznych, nie mają żadnych zależności. To znaczne utrudnienie dla AI, kiedy np. słowo „funkcja” może oznaczać pełnienie jakiejś roli, pojęcie matematyczne lub własność.
- Synonimiczność – słowa oznaczające to samo, co inne słowo lub zbliżone semantycznie. Analiza tekstu jest utrudniona, ponieważ synonimy są odrębnymi słowami. Synonimem „mały” może być „mini”. Co wyświetla Google, gdy wpiszemy w wyszukiwarkę „mały pies”?
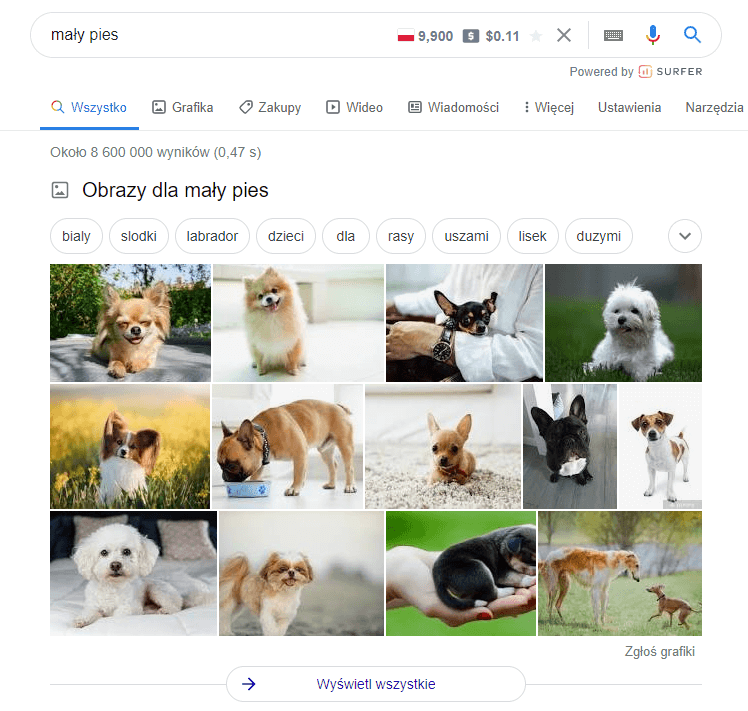
Posługując się synonimem tego wyrażenia w postaci „mini pies” otrzymamy:
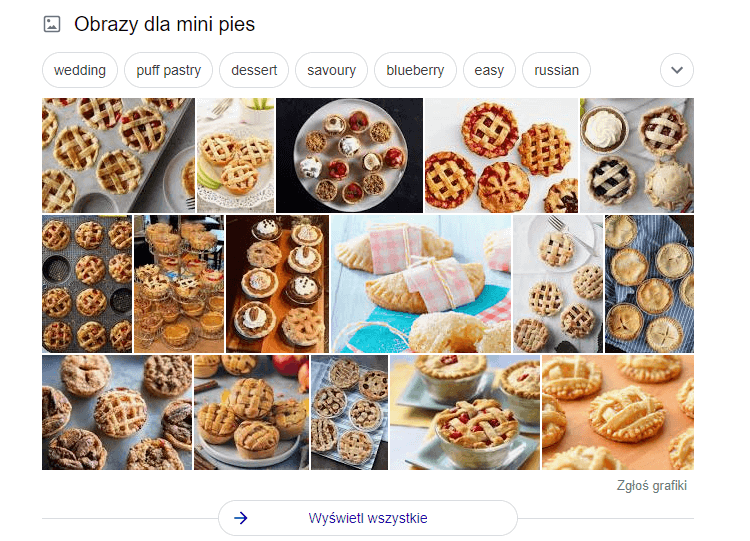
Pomimo tego, że BERT uczy się od 2019 r., nadal nie rozumie różnicy między „mini psem” a „mini pie”. Co prawda, w wyszukiwaniach podobnych sugeruje, że być może chodzi o “mini pieska’.
- Idiomatyczność – konstrukcje, których nie da się przeanalizować dosłownie ani przetłumaczyć na inny język: „it rains cats and dogs” nie oznacza deszczu psów i kotów, a przy znajomości słów „it,”, „rains”, „cats”, „and”, „dogs” bez świadomości językowej nie byłoby to takie oczywiste.
- Kontekstowość – główną rolę w rozumieniu komunikatów językowych odgrywa kontekst. W zdaniu „Weronika pożyczyła samochód” może chodzić o to, że Weronika pożyczyła pojazd komuś innemu lub, że to ona pożyczyła samochód od kogoś. Rozpoznanie celów, intencji czy planów jest warunkiem prawidłowej interpretacji zapytania, dlatego przed wprowadzeniem aktualizacji BERT prognozowano, że wpłynie on na ok. 10% wyników wyszukiwania.
- Koreferencja – czyli relacja między tym, o czym się mówi: „Wyjął ser z lodówki i położył go na kanapkę”. AI traci orientację w treściach, w których występuje dużo zaimków oraz odniesień.
Aktualizacja miała przede wszystkim poprawić jakość odpowiedzi na wyszukiwania long tailowe, ale też na hasłowe – analizując zapytania razem z RankBrain Google i zwracając wyniki, bierze pod uwagę m.in. poprzednie wyszukiwania, personalizację oraz lokalizację. Wymienione wyżej trudności wydają się banalne dla kompetentnego użytkownika języka, który podświadomie potrafi rozróżnić o kim/o czym mowa w tekście, w którym znajduje się dużo zaimków oraz radzi sobie z wieloznacznością w sposób intuicyjny. Dla maszyn długo nie było i do pewnego stopnia nadal nie jest to takie oczywiste. Przetwarzanie języka naturalnego zależy od zastosowanego modelu językowego. Dzisiaj wydaje się, że Google „czyta nam w myślach”, co jest zasługą rewolucji w NLP, jaką jest kontekstowa analiza języka.
2. Modele językowe – od n-gramu do architektury transformera
2.1 N-gramy
Statystyczne modele przetwarzania języka naturalnego, czyli na przykład model n-gramowy, opierają się na prawdopodobieństwie i częstości występowania po sobie konkretnych składowych języka, takich jak sylaby lub fonemy. N-gram to sekwencja elementów o stałej długości: unigramów, bigramów i trigramów, gdzie bigramem będzie np. fraza „las deszczowy”. Dysponując dużą bazą słów oraz wyrażeń, czyli korpusem, można przewidywać sekwencje językowe, co stosuje się m.in. przy kampaniach Google Ads, w których analiza n-gramów pomaga w wykluczaniu słów kluczowych i dostosowywaniu stawek. Chociaż jest to bardzo efektywna metoda to szacowanie prawdopodobieństwa zawodzi, gdy mamy do czynienia z nieznanym dotąd słowem. Ponad 15% zapytań wpisywanych codziennie w wyszukiwarkę Google jest nowych, a modelowanie statystyczne najlepiej sprawdza się w przewidywaniu sekwencji słów, które wystąpiły w korpusie treningowym.
2.2. Osadzanie słów
Od 2013 r. do analizy zapytań użytkowników Google zaczęło korzystać z tzw. wektorów dystrybucyjnych, czyli osadzania słów (ang. word embedding), opartych na sieciach neuronowych i macierzy współwystępowania. Clue tej metody NLP jest założenie, że słowa stosowane w podobnym kontekście mają podobne znaczenie. Zespół Google stworzył Word2vec, będący połączeniem kilku modeli, które z powodzeniem kojarzą słowa i umieszczają je w odpowiednim kontekście. W praktyce oznacza to, że model językowy jest w stanie ocenić bliskość semantyczną słów kot-pies w porównaniu np. do pies-jabłko. Inaczej mówiąc: Word2vec wskazuje, które słowa są powiązane i w jaki sposób. Osadzanie słów zwiększyło możliwości analizy języka pod kilkoma względami, w tym w kontekście nacechowania emocjonalnego (analiza sentymentu). Jednak nadal nie rozwiązało problemów charakterystycznych dla języka naturalnego, głównie wieloznaczności.
2.3. Architektura transformera (mechanizmu uwagi)
Abstrakcyjność i polisemiczność (wieloznaczność) to cechy języka, które sprawiają, że jego analiza wyłącznie na poziomie gramatycznym może powodować dojście do błędnych wniosków, dlatego modele oparte na statystyce, w tym model n-gramowy, nie są tak efektywne jak te wykorzystujące sieci neuronowe. Poza rozkładem prawdopodobieństwa biorą one również pod uwagę kontekst. Jest to efekt „uczenia się” sieci, które można porównać do poznawania świata przez małe dziecko. To na tym modelu opiera się działanie przełomowej aktualizacji Google – BERT. Co jest w nim tak wyjątkowego?
- Potrafi czytać nieotagowany tekst, co nie było wcześniej możliwe. Dzięki temu BERT uczy się na podstawie surowych próbek tekstu, bez konieczności angażowania zespołu nadzorującego, w tym lingwistów.
- Analizuje treść dwukierunkowo i symultanicznie! Może jednocześnie interpretować całe zapytanie wpisywane przez użytkownika, a nie wyłącznie pojedyncze słowa. Oznacza to, że może odczytać kontekst, nawet jeśli we wpisywanej treści występują wieloznaczności.
- Pozwala na stawianie hipotez i radzi sobie z wynikaniem tekstowym, oznaczając prawdopodobieństwo między fragmentami tekstu (x wynika z y) w sposób imitujący ludzkie myślenie, a nie za pomocą języka formalnego. Ocenia prawdopodobieństwo występowania, analizując strukturę oraz znaczenie. Dzięki temu może przewidzieć treść następnego zdania.
BERT przeczytał 2.5 miliarda słów z angielskiej Wikipedii. Ćwiczył także na treściach korpusowych. Analiza tak dużej ilości danych tekstowych powoduje, że wobec aktualizacji pojawiają się zarzuty, że nie jest niczym innym jak symulacją rozumienia kontekstowego i przypomina chiński pokój. Według Emily Bender i Alexander Kolle’a („Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”) modele językowe uczą się jedynie “odbitego znaczenia”, a analizowanie dużej ilości danych zaznajamia BERTa jedynie z formą oraz prognozowanym znaczeniem. Użytkownicy stale generują nowe formy komunikacyjne, za którymi nawet zaawansowany model językowy nie jest w stanie nadążyć.
3. Czy przetwarzanie języka naturalnego ma wpływ na SEO?
3.1. Co zmienił BERT w wynikach wyszukiwania?
Tak naprawdę…niewiele. BERT był aktualizacją, którego wprowadzenie nie wpłynęło w znaczący sposób na wyniki w SERPach. Przede wszystkim poprawił poziom zrozumienia nowych zapytań. Jednak fakt, że Google kładzie nacisk na jak najlepsze zrozumienie języka naturalnego, jest dobrą wskazówką do tworzenia treści skierowanych przede wszystkim do użytkowników. Dlaczego to takie ważne? Gdy w 2015 r. internauci zastanawiali się, co spotkało dinozaury, mogli poczuć się zaskoczeni:

Źródło: https://searchengineland.com/what-happened-to-dinosaurs-googles-direct-answer-gives-non-scientific-theory-from-religious-site-222934
Obecnie zwracanie wyników powiązanych semantycznie i „odgadujących” kontekst działa dużo lepiej, dlatego, jeśli w 2021 zastanowimy się, co spotkało dinozaury, odpowiedź będzie miała charakter naukowy:

Po zmianie wyszukania w propozycjach wyszukiwania pojawiają się frazy powiązane semantycznie:

BERT pomógł poprawić wyniki wyszukiwania, zwłaszcza na frazy long tailowe, dlatego jego wprowadzenie miało znaczenie przede wszystkim dla blogów. Powyższy przykład pokazuje, że skutecznie rozpoznaje powiązane terminy (what killed dinosaurs -> global extinction). Poza tym, jeśli BERT poprawił poziom analizy treści na zaindeksowanych stronach, tym ważniejsze powinno być, żeby content był dobrej jakości, ponieważ Google dysponuje instrumentami, żeby tę jakość ocenić.
3.2. Pozycjonowanie pod BERT – czy to możliwe?
Oficjalne stanowisko Google mówi, że w związku z BERT “nie ma nic do optymalizacji” i rzeczywiście od 2019 r. pod tym kątem niewiele się zmieniło. Aktualizacja była skierowana do użytkownika, ale pozycjonerzy mogą ją wykorzystywać:
- Tworząc content powiązany kontekstowo nie tylko w obrębie danej treści np. w artykule blogowym, ale w całej witrynie.
- Skupiając się na frazach long tailowych.
- Pisząc treści z wykorzystaniem grup fraz kluczowych.
Badania przeprowadzone z udziałem BERT i ELMO (“What do you learn from context? Probing for sentence structure in contextualized word representations”) wykazały, że najnowszy LM radzi sobie lepiej w zadaniach kontekstowych sprawdzających NLP, w porównaniu do LM opartych na tradycyjnej analizie, jednak głównie na poziomie syntaktycznym (składniowym), a nie semantycznym (relacyjnym). Co to oznacza? BERT nie radzi sobie np. z negacjami; umieszczenie “nie” i “nie może” w zadaniach testowych dla ML skutkowało różnymi wynikami w zależności od składni.
Podsumowanie
Czy Google rozumie wszystkie pytania? Uczące się algorytmy radzą sobie z większością wyzwań, jakie stawia przed nami przetwarzanie języka naturalnego, ale nadal brakuje im prawdziwego zrozumienia. Model językowy oparty na architekturze transformerów dobrze radzi sobie z wieloznacznością na poziomie zdań i wyrażeń, dzięki analizie relacji między poszczególnymi składowymi, jednak nadal pozostaje bezradny wobec polisemiczności hasłowej i niuansów emocjonalnych. Dlaczego, chociaż mamy 2021 r., a BERT przez cały czas się uczył, nadal są frazy lub wyrażenia, które mogą być problematyczne? Pandu Nayak, wiceprezes Google, przy wprowadzaniu aktualizacji powiedział, że „people’s curiosity is endless”. U podstaw zaspokojenia tej ciekawości leży zrozumienie języka, a ten nieustannie się zmienia. To jeden z argumentów przeciwko semantycznym umiejętnościom BERTa – stałe generowanie nowych zapytań powoduje, że aktualizacja zgaduje znaczenie na tej samej zasadzie jakby wnioskowała na podstawie składni (da się powiedzieć coś o zdaniu na podstawie samej jego budowy). Modele językowe nie biorą też pod uwagę ludzkich niedoskonałości – niskich kompetencji językowych i posiadania fałszywej wiedzy o świecie. Google może trafnie rozpoznawać intencje zapytań, ale pozostaje wątpliwe, czy sprawdza się w identyfikowaniu intencji komunikacyjnej, a to podstawowa funkcja języka i ważna część intencjonalności w ogóle.
Źródła:
https://www.blog.google/products/search/search-language-understanding-bert/
https://arxiv.org/abs/1908.09892
https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00298
https://searchengineland.com/google-reaffirms-15-searches-new-never-searched-273786




