To tylko kilka sekund przy komputerze: wystarczy wpisać coś w Google, trafić na Wikipedię i już można odnieść wrażenie bycia Ekspertem. W praktyce słynna internetowa encyklopedia pod względem wiarygodności jest zaledwie protezą jakiejkolwiek encyklopedycznej literatury. Idea anonimowości sprawiła, że treści na Wikipedii to głównie pauperyzacja wiedzy, którą niestety zbyt wiele osób bierze jako poważne źródło. Prawdopodobnie na tej pożywce wyrosło badanie Backlinko, które zdążyło się już pojawić w polskim internecie.
Autorzy wylosowali milion zapytań, pobrali dla nich TOP10 i następnie z tego wylosowali milion podstron do właściwej analizy. Celem miało być znalezienie korelacji. Czy zostały znalezione?
Na pewno nie w ten sposób
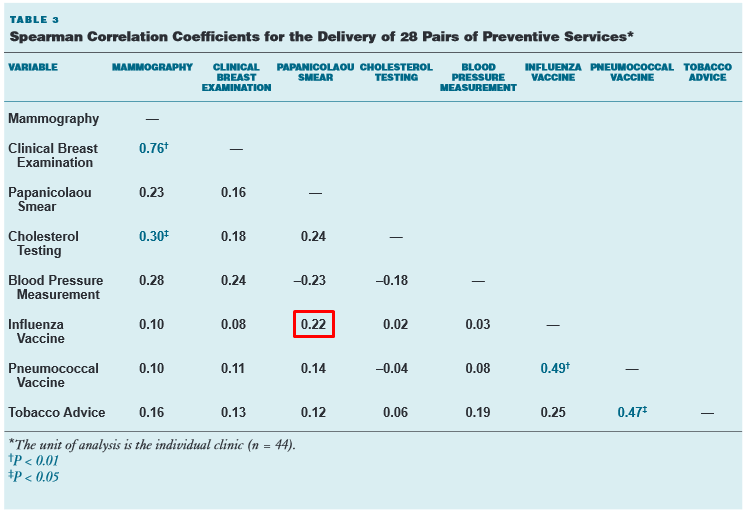
Przezornie na samym końcu dokumentu zostały podane współczynniki korelacji Spearmana, być może z nadzieją że nikt do nich nie dotrze. Niestety nawet najwyższy współczynnik, zgodnie z autorami „ekstremalnie ważny” i „silnie skolerowany”, wyniósł 0.20 co statystycznie jest najwyżej słabą korelacją (a w praktyce ciężko tu mówić o jakimkolwiek związku).
Dla porównania taka sama korelacja łączy pacjentów szczepiących się przeciw grypie i udających się na badania ginekologiczne:
Błędy interpretacyjne
Dalej jest niestety gorzej:
- 0.04 dla HTTPS
- 0.03 dla ilości słów na stronie
- 0.04 dla zgodności z tematem
- 0.05 dla Ahrefs Domain Authority
Nie pozostawiają najmniejszego pola manewru. Brak korelacji zgodnie ze Spearmanem. Mimo to autorzy analizy przy każdym z tych elementów stwierdzają z całą pewnością, że tu widać wyraźną korelację.
W takiej sytuacji pozostają tylko dwie opcje: albo autorzy posiadają dziesiątki dodatkowych danych którymi się nie podzielili albo nie mają pojęcia o czym mówią. Prościej sprawdzić drugą „hipotezę”. Niestety nie trzeba było długo szukać…
Otóż według słów Backlinko współczynnik Spearmana:
- jest najodpowiedniejszy przy szukaniu efektów wpływu zmiennych (w praktyce zawodzi przy korelacji nieliniowej, a do tego samego współczynnika raczej nie używa się bez dodatkowych testów)
- 0.070 jest dwukrotnie większy od 0.035 (współczynnik „nie zaczyna się” od zera, równie dobrze można powiedzieć że 6°C to dwa razy więcej niż 3°C)
- jest pewny od 0.03 jeśli jest takie mniemanie (klasyczne pseudonaukowe naciąganie danych pod wcześniej założoną tezę, w praktyce o istotnych współczynnikach nie mówi się wcześniej niż od 0.50)
W obliczu takich wypowiedzi trudno założyć, że pewność autorów raportu wynika z przeprowadzenia wielu testów T, odrzucania hipotez zerowych, kontroli jakości danych.
Wykresy które nic nie znaczą
Spostrzegawczy czytelnik na pewno zadał sobie pytanie: jak to jest że praktycznie nie ma związku w najsilniej skolerowanym elemencie (bardziej poprawnie: najmniej słabo skorelowanym) a na wykresie widać wyraźny trend?
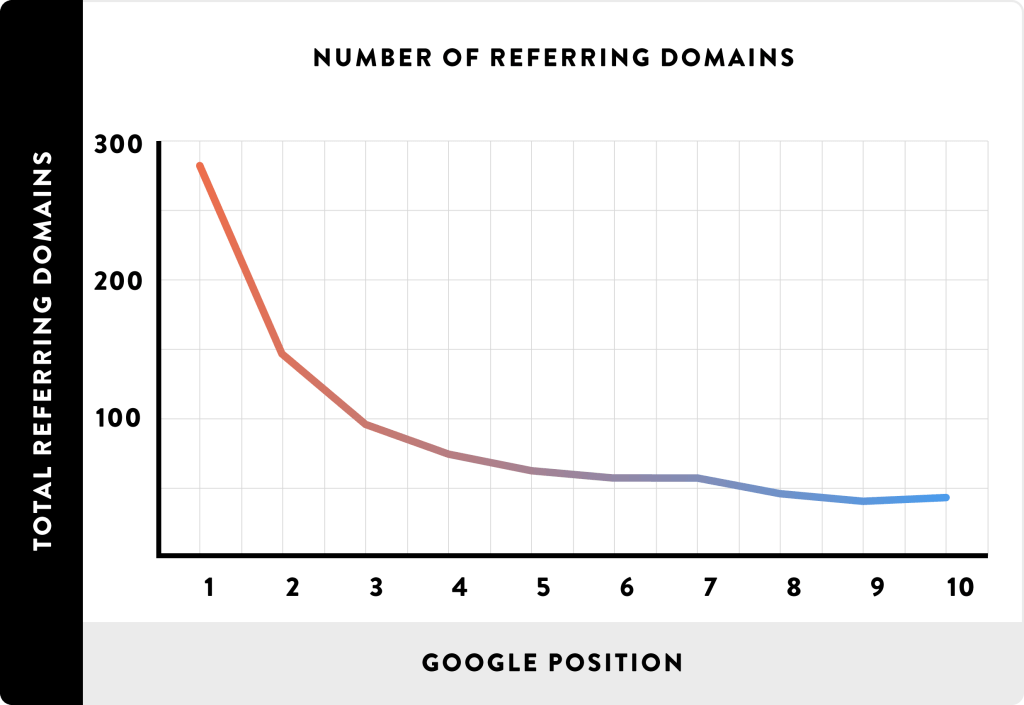
I to celne pytanie, którego autorzy „badania” prawdopodobnie sobie nie zadali. Otóż w tego typu danych zdecydowanie należy się spodziewać wartości odstających. Normalne jest, że strona na pierwszym miejscu może mieć nawet 1000 domen linkujących do niej – to nazywamy wartością odstającą. Współczynnik Spearmana jest dość odporny na tego typu wartości. Natomiast zaprezentowana na wykresie średnia jest dość wrażliwa na tego typu wartości. W efekcie by wywindować średnią do takiej postaci wystarczy, że dla części zapytań na pierwszych miejscach były strony Wikipedii (a jak wszyscy wiemy, Google je uwielbia i często są w TOP3), do których linkuje pół internetu.
Jeszcze wyraźniej widać to poniżej:

Gdzie przy współczynniku 0.04 na wykresie średniej jest trend, o który również można śmiało obarczyć Wikipedię w całości stojącą na HTTPS. Co ciekawsze, w pewnym momencie autorzy nawet o tym wspominają, jednak nie zasiało to w nich ziarna wątpliwości, że średnia jest tu źle dobranym narzędziem.
Nie ma potrzeby krytykować każdy wykres z osobna, pozostawiam to zdrowemu odbiorowi czytelnika. Wskażę tylko jeszcze jeden dobitny przykład, tym razem nie z powodu średniej:
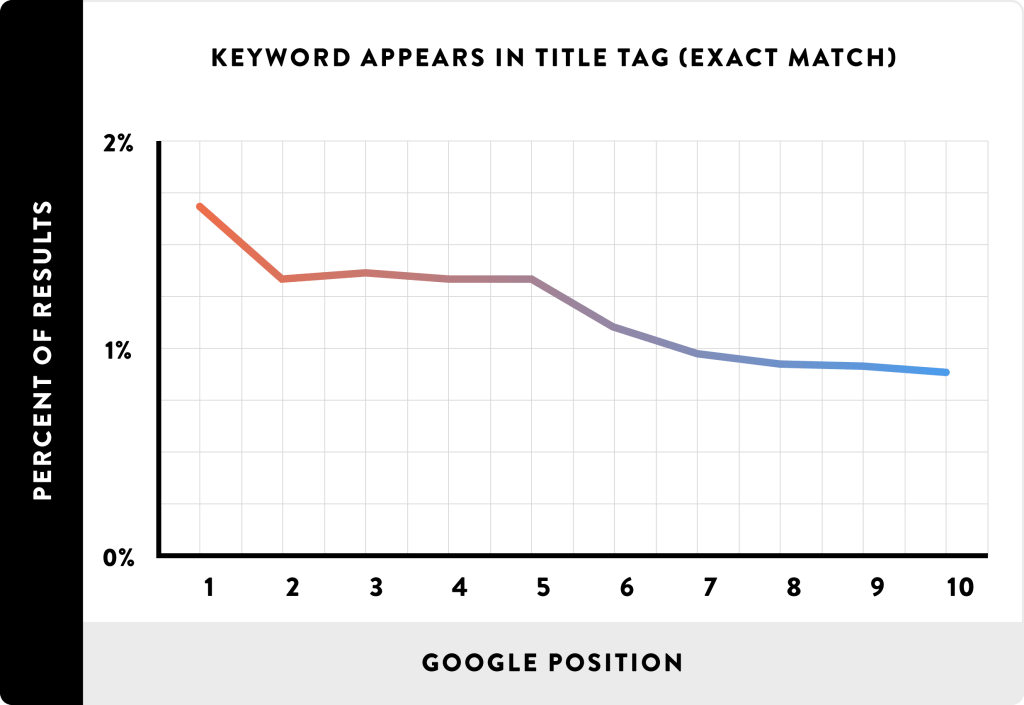
Tutaj wskazano obecność „exact match” (litera w literę) zapytania w tytule strony (metatag title). Badanie jak badanie, zawsze można to sprawdzić. Jednak Backlinko wyciągnęło z tego wniosek, że tytuł strony już w zasadzie nie wpływa na pozycjonowanie. Nadinterpretacja to mało powiedziane!
Dlaczego się nie udało?
Co jakiś czas duzi gracze publikują badania korelacji, które niestety – jak widać wyżej – często nie mają nic wspólnego nawet z podstawami statystyki. Podobnie krytyczne uwagi da się bez problemu znaleźć w odniesieniu do Moz czy Searchmetrics. Można powiedzieć: spróbujcie sami skoro wytykacie błędy. Co wnieślibyśmy stosując poprawne narzędzia statystyczne i realną interpretację?
Nic. Żaden dotychczasowy raport nie wykazał silnej liniowej korelacji. By wykazał, potrzebne jest wykrycie i ograniczenie wpływu wielu czynników pełniących rolę wartości odstających takich jak: filtry algorytmiczne, kary ręczne, chwilowe awarie, zmiany i eksperymenty w algorytmach, personalizacja wyników pod kątem lokalizacji, trwające kampanie linkowania, disavow, historia domeny, konkurencja. To wszystko ma często decydujący wpływ na pozycję i nie jest uwzględniane w jakimkolwiek badaniu korelacji. Ciężko zresztą mówić o nich per „badanie”, bo brakuje w nich naukowej metodologii, narzędzi, interpretacji i w końcu recenzji. Nie każde kilka cyfr jest badaniem.
To trochę tak jakby próbować szukać korelacji do wyniku wyścigu. Sprawdzić czy refleks kierowcy albo przyczepność opon korelują z pozycją na mecie. Można w to zainwestować czas i nic się nie dowiedzieć, a można też postawić na realne testy/eksperymenty i z nich wyciągnąć wartościowe wnioski. Nawet dowody anegdotyczne są bliższe rzeczywistości niż próba wyciągnięcia korelacji dla jednego z dwustu czynników.
Zalinkowane źródła: Backlinko.com, Takaoto.pro, Ecp.acponline.org, Irthoughts.wordpress.com. Źródła grafik: Facebook.com, Ecp.acponline.org, Backlinko.com.
3 komentarze
Szymon Słowik
Cześć Rafał. Dzięki za wnikliwe przyjrzenie się sprawie.
Krytyka ostra i muszę przyznać, że wydaje się w dużej mierze zasadna. Jednak parę uwag wobec niej też muszę wysunąć.
1) Losowy milion wydaje się być reprezentatywną próbą.
2) Wpływ FB i Wiki na wysokie pozycje w kontekście chociażby https nie musi deprecjonować jednoznacznie tego czynnika. Ponadto autorzy badania w opisie metodologii o tym wspominają.
3) Z jednej strony wsp. korelacji w okolicach 0.2 uznawany jest za słabą zależność. Z drugiej strony właśnie biorąc pod uwagę dużą różnorodność próby, ciężko byłoby oczekiwać bardzo silnych liniowych zależności. Ciekawe by było w tym kontekście przeprowadzenie badań uwzględniających poszczególne segmenty witryn (wiki, sociale, fora, strony firmowe, blogi etc.). Podejrzewam, że dla zapytań stricte komercyjnych, gdzie w topie jest 10 stron ofertowych, zupełnie inne czynniki mogą mieć znaczenie, niż zapytania poradnikowe etc.
5) Zgadzam się, że badanie nie jest badaniem naukowym i nie można używać go jako dowodu per se. Niemniej jest zbiorem przesłanek i uznanie go za bezwartościowe to chyba przesada.
6) Wszystkie wnioski należy zderzyć z własnymi doświadczeniami i testować (tak działają przesłanki). Nieraz spotkałem się z tym, że w jednych tematach posiadanie 15 razy więcej linków nic nie daje. W niektórych niszach wdrożenie RWD robiło różnice, w innych nie było zauważalnych wzrostów.
7) Przeprowadzenie stricte naukowego badania w SEO wydaje mi się być praktycznie niemożliwe w kontekście ogółu wyników (nie mówię tu o pojedynczych testach na konkretnych witrynach). Jak słusznie wspominasz, ciężko oczyścić dane z czynników związanych chociażby z kwestii związanych z filtrami Google. Ponadto trzeba by uwzględnić, jak długo strony są na określonych pozycjach, czy cechują się stabilnością. Moim zdaniem to warunek, aby wyciągać jakiekolwiek wnioski np. na temat stron z pozycjami top3. SEO jest różnorodne i czym innym jest wbicie strony do topów na dwa tygodnie (i wówczas dane dowiodą, że np. linki z exact-match anchor tekstem super korelują z pozycjami na dane frazy) a czym innym budowanie „stabilnych” pozycji w długiej perspektywie.
8) Jeszcze jedną rzecz należy wytknąć w tym kontekście. Badanie nie uwzględnia (bardzo ciężko by to było zrobić) aspektu dynamicznego. To, że strona dzisiaj jest wysoko na frazę x i że ma dużo linków z anchorem x wcale nie oznacza, że te linki mają wpływ. Mogą być dawno w disavow toolu. Mogą nie być brane pod uwagę. Mogą też być uznawane jako czynnik niegroźny jeśli linki są stare, ale w przypadku świeżego przypływu linków strata pozycji mogłaby paradoksalnie nastąpić. I takie sytuacje się zdarzają.
Podsumowując, z Twoją krytyką warto się zapoznać. Dla uczciwości podlinkuję ten tekst również w opublikowanym przez nas wpisie, do którego się odnosisz.
Kamil Rybicki
Generalnie jeśli metodyka badania jest zła, to niezależnie od wielkości próby wyniki nie mogą być wiarygodne. Analogicznie, jeżeli na podstawie „przebadania” 1 000 000 samochodów, które nie uczestniczyły w wypadku w ciągu 2 lat dojdę do wniosku, że jest silna korelacja między posiadaniem na wyposażeniu odświeżacza powietrza, a bezpieczeństwem to mój wynik będzie wiarygodny?
Ps. Dziękujemy za podlinkowanie. Jak już gdzieś wcześniej pisałem, nawiązanie do Twojego wpis nie było atakiem z naszej strony, bo bardzo Cię szanujemy jako specjalistę. Jako pierwszy opracowałeś w Polsce opracowałeś te wyniki, dlatego do nich zalinkowaliśmy. Co złego to nie my 🙂
hauerpower.com
sprawa jest bardzo indywidualna bo co branża to inna konkurencja i inne standardy, w jednej branży wystarczy działanie X w innej niestety trzeba zrobić lekko co innego, również tolerancja na linkowanie i anchory jest bardzo różna.