
Odkrywcą błędu jest Tom Anthony.
Tom kreatywnie wykorzystał (znane w świecie SEO od lat) otwarte przekierowania. Wiele stron, w tym zdecydowana większość gigantów internetu, posiada adres z parametrem, który pozwala na przekierowanie – zazwyczaj służy do wyjścia z domeny lub do powrotu po zalogowaniu do poprzednio oglądanej podstrony. Przykładowo na Allegro.pl to m.in. parametr origin_url:
https://allegro.pl/login/form?authorization_uri=...%3Fclient_id%3D...%26redirect_uri%3D...%3F
origin_url%253Dhttps%25253A%25252F%25252Fallegro.pl%25252Fmoje-konto
Zgodnie z przeznaczeniem, tego typu przekierowanie zazwyczaj dochodzi do skutku dopiero po zalogowaniu, ale zdarza się, że parametr może być użyty w dowolnym momencie, a także w stosunku do dowolnego adresu. W ten sposób można utworzyć adres ObcaDomena.pl/?przekierowanie=DrugaDomena.pl, który przekieruje wchodzącego na DrugaDomena.pl. Takie wykorzystanie przekierowania jest (w niektórych przypadkach: było) dostępne w Google.com, Facebook.com, Linkedin.com, Tesco.com i u wielu innych. To na tyle popularny błąd, że we wspomnianym programie łowców błędów został wyłączony z nagradzania.
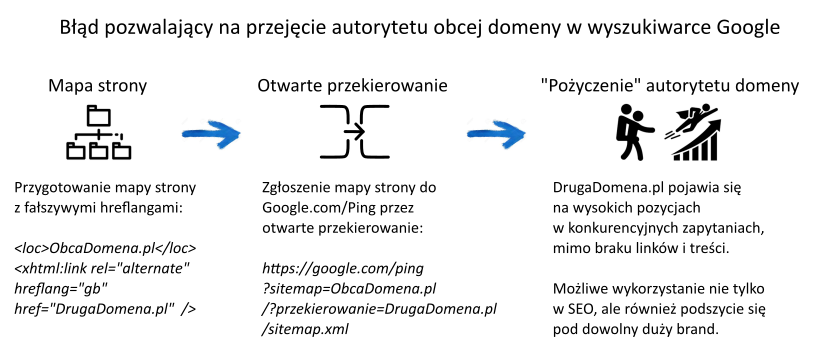
Co gdyby za pomocą otwartego przekierowania spróbować przekonać wyszukiwarkę, że silna, obca domena jest nasza?
To był strzał w dziesiątkę!
Wystarczyło wysłać do Google.com/ping przekierowanie z obcej domeny do mapy strony na własnej domenie:
https://google.com/ping?sitemap=ObcaDomena.pl/?przekierowanie=DrugaDomena.pl
Robot indeksujący podążał za przekierowaniem, przekonany, że odczytuje mapę strony powiązaną z obcą domeną – przez co przypisywał autorytet obcej domeny do adresów obecnych w tej mapie. Tom za pomocą takiej implementacji błyskawicznie osiągnął wysokie pozycje czystą, świeżo zarejestrowaną, własną domeną:


Co więcej, Google Search Console wyświetlało obcą domenę nawet w linkach:

Adresy w mapie strony, mimo że należące do innej domeny, otrzymały autorytet oryginału, dzięki użyciu tagów hreflang.
To bardzo głęboka luka. Autor, z całkowicie czystymi intencjami, w niewielkim czasie pokazał, że może pojawiać się w wyszukiwarce na pozycjach wartych dziesiątki tysięcy dolarów. Jego jedyną inwestycją było kilkanaście dolarów na rejestrację nowej domeny, a także chwila czasu na odpowiednie wysłanie mapy strony. Co prawda zarówno on jak i pracownicy Google twierdzą, że prawdopodobnie nikt tego nie wykorzystywał, ale sam fakt istnienia tak spektakularnego błędu w blisko 20-letniej wyszukiwarce jest interesujący.
Trudno przypomnieć sobie podobne, równie efektowne wpadki w ostatnich latach. Lukę można było wykorzystać nie tylko na potrzeby klasycznego SEO – za jej pomocą można było przeprowadzić masowy phishing prosto w wyszukiwarce, co mogło skończyć się katastrofalnie w przypadku podszywania pod gigantyczny sklep typu Tesco.com.
The right thing
Tom Anthony dość szybko zgłosił błąd do firmy Google we wrześniu 2017. Po wielomiesięcznej korespondencji, dopiero w marcu 2018 błąd został usunięty – aktualnie tagi hreflang są ignorowane w mapach stron zgłoszonych przez Google.com/ping. Ich poprawne odczytywanie jest możliwe tylko w mapach wskazanych w robots.txt lub w GSC, co w oczywisty sposób ogranicza ich użycie tylko do właścicieli stron.
Między wierszami
Likwidacja błędu zajęła pracownikom Google aż 6 miesięcy. Po pierwszym miesiącu zgłaszający błąd usłyszał:
Ten raport jest trudny do sprecyzowania – co można zrobić by zapobiec takiemu wykorzystaniu, a także na ile wpływa na nasze wyniki wyszukiwania.
W późniejszych miesiącach musiał regularnie prosić o aktualny status sprawy. Tom konkluduje, że współpraca z Google była przyjemnością, ale nie da się nie zauważyć, że trafił na osobliwie łagodną i długą reakcję – zarówno w stosunku do rozmiarów błędu jak i w kategoriach ogólnych standardów działów zajmujących się bezpieczeństwem IT.
Prawdopodobnie przyczyny należy szukać w ogromnej ilości zgłaszanych błędów – w każdej roboczogodzinie blisko 2000-3000 nowych:
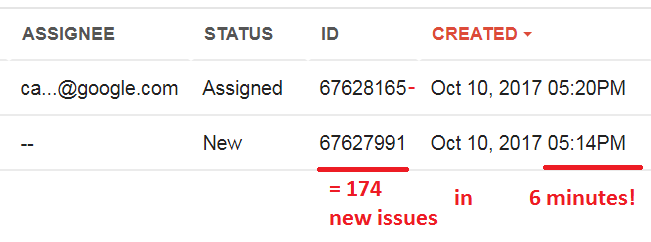
(O czym wiemy, dzięki… innej luce w systemach Google. Polecamy świetną relację.)
Jednak pierwsza odpowiedź i tok reakcji pozostawia niewielkie ziarno wątpliwości odnośnie poziomu troski spółki Alphabet o organiczną część swojego flagowego produktu. Dalsze przemyślenia w tej sprawie pozostawiamy czytelnikom.
Od strony zupełnie technicznego SEO, otrzymaliśmy kolejne dobitne potwierdzenie istnienia autorytetu domen w wyszukiwarce, ich ogromnego wpływu na kolejność wyników wyszukiwania, a także zaskakująco istotnej roli tagów hreflang. Co zabawne, publikacja błędu zbiegła się na przestrzeni dosłownie kilku dni z Johnem Muellerem standardowo zaprzeczającym istnieniu autorytetu domeny. Wydaje się zresztą, że sam John Mueller nie słyszał o opisanym i już naprawionym błędzie…
Zalinkowane źródła: Google.com, TomAnthony.co.uk, Medium.freecodecamp.org, Nprofit.net, Searchenginejournal.com. Źródła grafik: TomAnthony.cio.uk, własne, Medium.freecodecamp.org.





5 Responses
Autorytet domen, bez względu jak go nazwiemy (PR, TR itp) istnieje i ma się dobrze, to ze wyszukiwarka nie wyświetla zielonego paska nie oznacza przecież że z niego zrezygnowała System „ważności” domen jest fundamentem rankingu.
Ciekawy przypadek. Czas naprawienia błędu w algorytmie mnie osobiście nie dziwi – Google jest tak duże, że to po prostu musiało potrwać. Na samym algorytmem ustalania pozycji działa pewnie kilkanaście osób z mniejszym lub większym pojęciem, co i kto wprowadzał wcześniej. Natomiast ilość zgłoszeń jest konkretna. To pewnie też zaważyło.
Dobrze, że istnieją jeszcze takie Dobre Mirki 🙂
Jak dobrze przeczytać ciekawy tekst SEO, w gąszczu nudnych tekstów i poradników.
Fajny tekst potwierdzający dlaczego tak dużo stron z oczywistymi i najprostszymi błeami on site ale starych, z dużym autorytetem domeny rankuje tak wysoko.
Ogólnie ostatnio Google chyba znów zaczął faworyzować stare domeny kosztem młodszych, nawet dobrze zoptymalizowanych.